Edmunds' GraphQL Federation Adoption (Part 1)
Yuhan Zhang, Suresh Narasimhan
This will be a 2 part series on our journey to adopting Graphql federation. In the first part, we explain why we adopted GraphQL federation and a short introduction to federation. In the second part, we will cover aspects of schema design, persisted queries, and how we achieved CD for graphQL with canary.
The Beginning
In our journey from migrating away from in-memory distributed store coherence, we started wrapping our datasets with microservice APIs. With these APIs able to scale independently along with the NoSql database they were communicating with
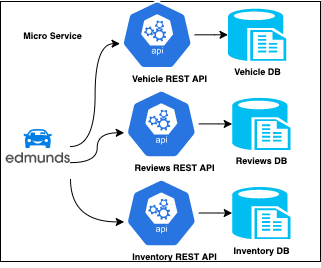
Over a while, our APIs evolved from a few APIs to many as the use cases continued to grow. With this, a few patterns started to develop.
- Discoverability - With many APIs, discovering them was an issue for the client. It was hard to narrow down on the proper API from the documentation
- Over and Under Fetching - There were also cases of over-fetching where the client had to request more than what they needed and under fetching where they had to make multiple calls to get what they needed
- Need For Aggregate APIs - BFFs were introduced, which aggregated several microservices together to make a meaningful API to the website or mobile app. (For example, our rankings page for SUV needs vehicle data and ranking data, which are kept in separate microservices. Without BFF, a mobile app would make multiple calls to the server and be delayed by round trips to render a page. A BFF API helps reducing calls into 1 for the page to get all data.)
We were not alone in facing these issues; several companies, including Netflix wrote about similar issues with REST services and why they chose GraphQL Federation. The growing need at an industry level to solve these issues led to the introduction of GraphQL
Netflix found that “Independent services allow for evolving at different paces and scaling independently. Yet they add complexity for use cases that span multiple services. Rather than exposing 100s of microservices to UI developers, Netflix offers a unified API aggregation layer at the edge … [GraphQL Federation] solves many of the consistency and development velocity challenges with minimal tradeoffs on dimensions like scalability and operability.”
We attempted to solve the under-fetching and over-fetching problems with our partial response API REST standard: using HTTP query strings as query conditions, applying field projection, and HTTP status to indicate success & failure.
GraphQL First Attempt
When GraphQL was open-sourced in 2015. The spec attempted to solve the issues we faced with an industry standard; this led to the introduction of GraphQL in Edmunds. From the onset, we realized for GraphQL to work to its full potential, we needed to join datasets together. Our first attempt was to power our rankings page with GraphQL calls. In our first attempt at GraphQL, we did not create separate artifacts for graphQL subgraphs. We wanted to move to graphQL incrementally and still have a separation of concerns so, we leveraged our existing rest APIs and joined them with a central graphQL server.
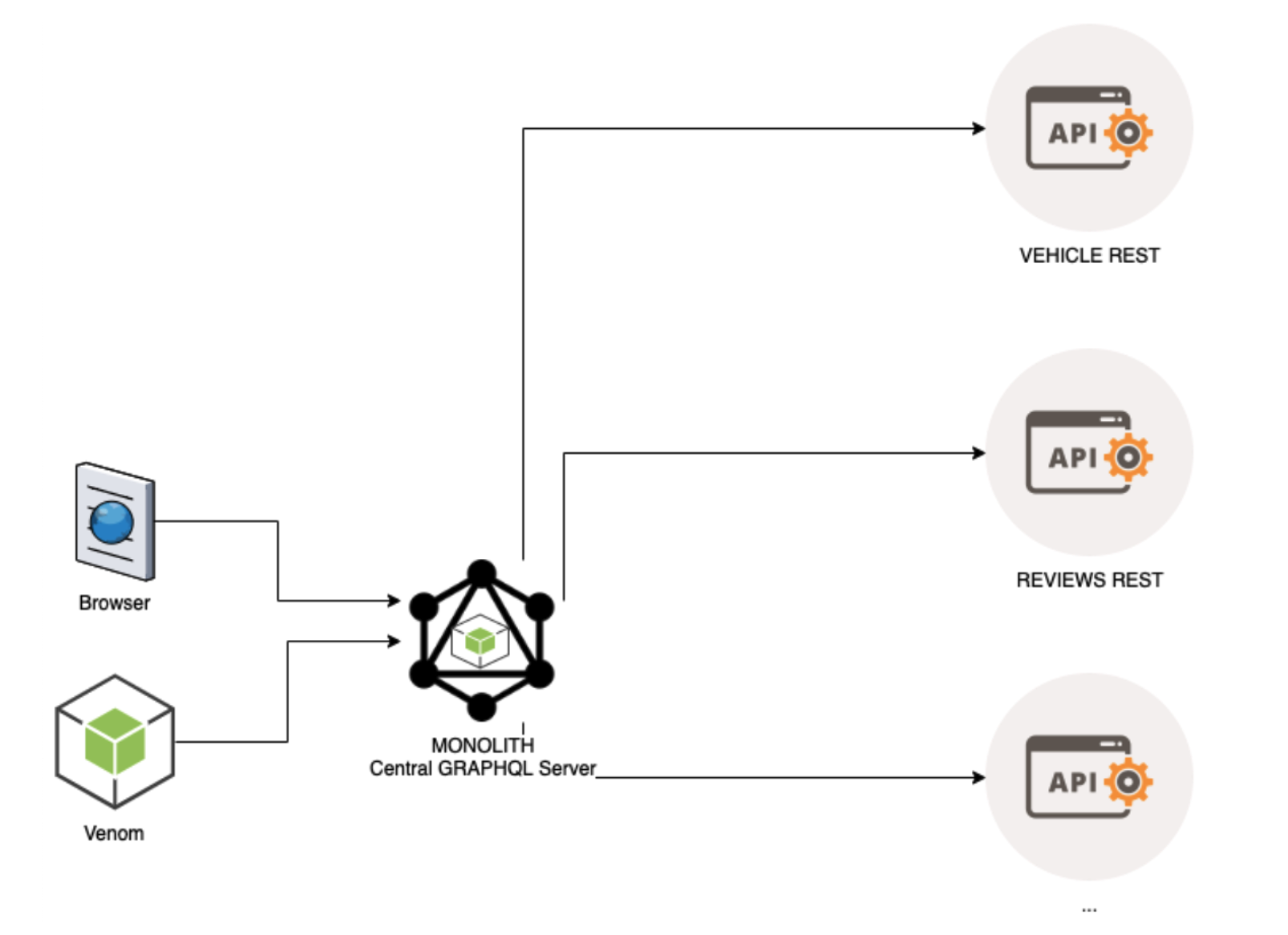
We launched this in production successfully. Some issues we noticed with our initial GraphQL design are as follows:
- Central GraphQL is a monolith and houses all the schema and resolvers.
- Central schema is dependent on REST APIs, making it cumbersome to evolve REST and GraphQL independently. This is inefficient and led to a proliferation of REST API calls.
- Before optimization and caching, a single GraphQL call made as many as 300 REST API Calls and took as much as 500-800ms . We used Dataloaders (shrunk multiple id calls into one call with multiple ids) and caching to mitigate the issue
Apollo introduced schema stitching. We attempted to use it but noticed issues with it so did not switch to using it.
Switch to Federation
Apollo Federation is a declarative way of implementing GraphQL in a microservice architecture. It’s designed to replace schema stitching and solve pain points such as coordination, separation of concerns, and brittle central server code.
When Apollo introduced GraphQL Federation , we were quick to attempt a POC to validate. It solved the pain points for remote stitching. The POC worked well, so we rewrote our rankings use case, replacing the central graphQL server with NodeJs based Apollo Federation server and wrote new GraphQL endpoints in our Java REST API artifacts.
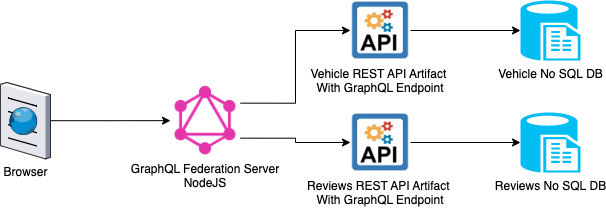
Introduction to Federation
Apollo Federation is a powerful open-source architecture that helps you create a unified supergraph that combines multiple GraphQL APIs:In a federated architecture, your individual GraphQL APIs are called subgraphs, and they’re composed into a supergraph. By querying your supergraph, clients can query all of your subgraphs at the same time.
Subgraphs can be managed/developed by different teams. For example, we have a subgraph called vehicle-graphql that fetches data about the make, model, and year of cars. A different team owns a subgraph called review-graphql that fetches consumer review data about a car. To add reviews resolver on an existing vehicle type, the review-graphql team only needs to specify the required fields in its own schema to fetch review data.
type VehicleModelYear @key(fields: "id") @extends {
id: ID! @external
make: String @external
model: String @external
year: Int @external
vehicleReviews(reviewFilter: ReviewFilter): Reviews @requires(fields : "id make model year")
}
The review-graphql does not fetch vehicle data - it doesn’t need to; vehicle-graphql doesn’t know review-graphql at all; The federation service fetches all the required parameters from vehicle-graphql and passes that to review-graphql automatically. The two subgraphs are in perfect separation of concerns.
How GraphQL Federation gets schema from Subgraphs
ApolloGateway (federation server) will query each GraphQL microservice (subgraph) with a { _service {sdl} } query during start-up to get its schema. Whether your subgraph is implemented in NodeJS, Java or other languages, if you are able to get the GraphQL engine to answer this query, the subgraph can be included in the supergraph schema in the federation server. Conflicting schema in the subgraphs will cause the federation server unable to start.
We used graphql-java library to construct a subgraph with federation support. To join multiple subgraphs, ApolloGateway will ask the subgraph for entities. Thus a function to .fetchEntities is necessary to be defined and passed to the schema. The method .resolveEntityType maps a Java class to a GraphQL type.
GraphQLSchema schema = Federation.transform(sdl.getFile(), buildWiring())
.fetchEntities(this::fetchEntities)
.resolveEntityType(resolveTypeResolvable())
.build();
(… to be continued in Part 2)
 Yuhan Zhang is Tech Lead on the Service Engineering team at Edmunds.
Yuhan Zhang is Tech Lead on the Service Engineering team at Edmunds.
 Suresh Narasimhan is Engineering Director on the Service Engineering team at Edmunds.
Suresh Narasimhan is Engineering Director on the Service Engineering team at Edmunds.
Do projects like this interest you? Edmunds is hiring: https://www.edmunds.com/careers/
